Beneath a Steel Sky - Back *With* the Future I
| tags: Amiga BASS translation Esta serie de posts trata sobre cómo las LLMs han ayudado a parchear y traducir al español Beneath a Steel Sky (a partir de ahora, BASS para los amigos) para Amiga.
Esta serie de posts trata sobre cómo las LLMs han ayudado a parchear y traducir al español Beneath a Steel Sky (a partir de ahora, BASS para los amigos) para Amiga.
En este post introductorio a la traducción de BASS para Amiga al español cubriremos la extracción de recursos del juego para PC y Amiga, así como un análisis de los recursos y cómo el juego trata el texto. Pero antes de empezar, un poco de info sobre el juego.
BASS es una aventura gráfica desarrollada por Revolution Software, publicada por Virgin Interactive en 1994. Inicialmente se publicó en la friolera de 15 discos de 3,5", aunque más adelante se lanzó en CD incluyendo voces digitalizadas y música. Probablemente sea el último gran juego de este tipo lanzado oficialmente para la plataforma ya que en abril del 94, Commodore se declaró en bancarrota.
En esta versión para Amiga parece ser que se recortaron varias animaciones para reducir espacio y tiempos de carga y evitar también el constante cambio de disquetes. También se convirtieron gráficos de PC a 256 colores al formato Amiga OCS de 32 colores simultáneos. Debemos tener en cuenta que la versión de Amiga es capaz de ejecutarse sin problemas en un Amiga con 68000 de serie y 1 MB total de RAM.
Además, por lo que he podido ver (ya lo veremos más adelante), todos los elementos de texto referentes a la interfaz (y algunos más) se reubicaron al propio ejecutable de Amiga.
Sobre todas estas dificultades y la situación que se debieron encontrar los desarrolladores, me gustaría destacar un mensaje que aparece dentro del binario (fichero ejecutable) del juego, en el offset 0xcf, donde bromean sobre las dificultades de portar el juego a Amiga:
At the beginning the programmers were happy and did rejoice at their task, for the Amiga before them did shineth and was full of promise. But then they did look closer and did see'th the awful truth; it's floppies were tiny and sloweth (rareth was its hard drive). And so small was it's memory that did at first appear large; queereth also was its configuration(s). Then they did findeth another Amiga, and this was slightly different from the first. Then a third, and this was different again. All different, but not really better, for all were psuedo backward compatible. But, eventually, it did come to pass that Steel Sky was implemented on a 1meg os-legal CBM Amiga. And the programmers looked and saw that it was indeed a miracle. But they were not joyous and instead did weep for nobody knew just what had been done.
Como curiosidad y guiño a la gesta de la implementación original, si echamos un ojo al código fuente de ScummVM, podremos observar el siguiente comentario:
At the beginning the reverse engineers were happy, and did rejoice at their task, for the engine before them did shineth and was full of promise. But then they did look closer and see'th the awful truth; its code was assembly and messy (rareth was its comments). And so large were its includes that did at first seem small; queereth also was its compact(s). Then hey did findeth another version, and this was slightly different from the first. Then a third, and this was different again. All different, but not really better, for all were not really compatible. But, eventually, it did come to pass that Steel Sky was implemented on a modern platform. And the programmers looked and saw that it was indeed a miracle. But they were not joyous and instead did weep for nobody knew just what had been done. Except people who read the source. Hello.
With apologies to the CD32 SteelSky file.
Me parece un puntazo de guiño. Debo decir que el texto original estaba en todos los ejecutables del juego que he visto (inglés, alemán, francés, italiano y sueco), no es exclusivo de la versión de CD32.
Antes de empezar, os pongo un poco en contexto: hace no mucho, se comentaba por un grupo de preservación de software en español que la aventura gráfica Beneath a Steel Sky nunca tuvo una versión en español para Amiga. Parece ser que la versión española sí se lanzó para PC, pero por lo que sea no quisieron hacer una versión española en Amiga.
En Amiga lanzaron el juego de manera oficial en los siguientes idiomas:
- Alemán.
- Francés.
- Inglés.
- Italiano.
- Sueco.
¿Y el español? Pues no. ¿Por qué? Pues porque no.
En este caso se han usado los textos originales de la versión española de PC, pero como veremos más adelante se han creado herramientas para poder realizar una traducción libre con medios modernos.
Extracción de recursos
La idea principal de este proyecto fue la de utilizar la traducción oficial de PC para poder “reinsertarla” en los ficheros de recursos de la versión de Amiga. Para ello, necesitamos dos cosas:
- Extraer los recursos de PC.
- Extraer los recursos de Amiga.
Parece bastante simple pero tal y como veremos a continuación (sobre todo con la versión de Amiga) nos encontraríamos con varios obstáculos que salvar.
Recursos de PC
Bien, tras un análisis inicial de la distribución del juego en PC, tenemos los siguientes ficheros de recursos:
| Nombre | Propósito |
|---|---|
SKY.DSK |
Contenedor de todos los recursos / “disco virtual”. |
SKY.DNR |
Índice/directorio. Indica que X recurso está en tal offset. |
Estructura
Los textos no aparecen en claro, pero con ayuda de LLMs se pudo ver que existe una tabla que para cada recurso, permite acceder a un mensaje concreto sin decodificar todo lo anterior. Además, el sitio donde apunta es un stream de bits comprimido con Huffman. Aquí un esquema:
SKY.DNR (índice)
|-- entry: id=60656 -> offset=0x123456, size=0x025A
|-- entry: id=60657 -> offset=0x126B2A, size=0x018E
|
`-> SKY.DSK (blob de datos)
offset=0x000000 [ .... ]
offset=0x123456 [60656 data, size=0x025A]
offset=0x1236B0 [ .... ]
offset=0x126B2A [60657 data, size=0x018E]
offset=0x126CB8 [ .... ]
Vendría a ser algo como esto:
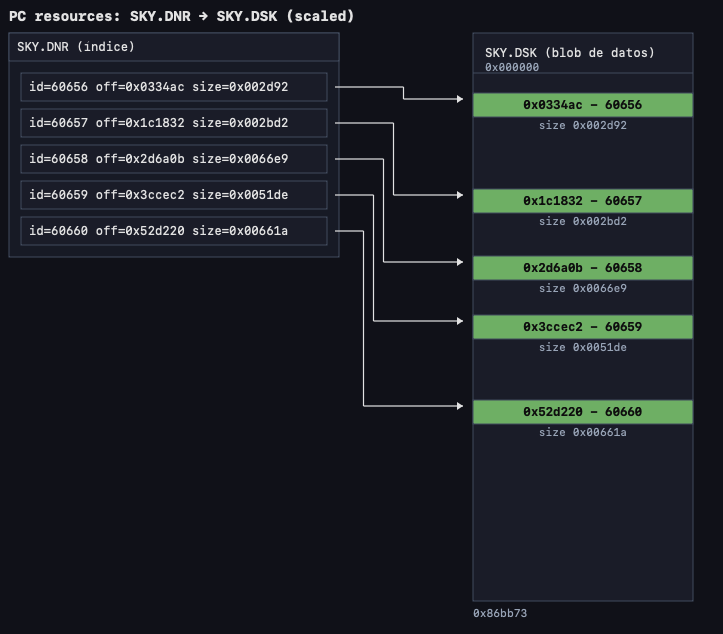
Esto significa que para acceder al recurso con id 60656 dentro de SKY.DSK, debo buscar primero su offset inicial, tamaño y offset final en SKY.DNR, luego ir a dicho offset inicial del fichero SKY.DSK y extraer la cantidad de bytes indicada en el tamaño, hasta offset final. En este caso, como veremos a continuación, esos datos corresponderán a un churro de bits comprimido con Huffman.
Hay varios tipos de recursos. Normalmente casi todo lo que no es texto (como animaciones, algunos gráficos, sonido, etc…) viene comprimido con RNC. En nuestro caso nos interesan los textos.
Por ejemplo, aquí tenéis una lista de algunos ejemplos de los recursos de la versión PC:
| ID | ID_HEX | OFF_HEX | SIZE_HEX | END_HEX | TIPO | FLAGS |
|---|---|---|---|---|---|---|
| 60663 | 0xecf7 | 0x1c4404 | 0x0007f1 | 0x1c4bf5 | TEXT_HUFF | S |
| 60662 | 0xecf6 | 0x834e40 | 0x000a80 | 0x8358c0 | TEXT_HUFF | S |
| 60661 | 0xecf5 | 0x6a057d | 0x0034a4 | 0x6a3a21 | TEXT_HUFF | S |
| 60660 | 0xecf4 | 0x52d220 | 0x00661a | 0x53383a | TEXT_HUFF | S |
| 60659 | 0xecf3 | 0x3ccec2 | 0x0051de | 0x3d20a0 | TEXT_HUFF | S |
| 60658 | 0xecf2 | 0x2d6a0b | 0x0066e9 | 0x2dd0f4 | TEXT_HUFF | S |
| 60657 | 0xecf1 | 0x1c1832 | 0x002bd2 | 0x1c4404 | TEXT_HUFF | S |
| 60656 | 0xecf0 | 0x0334ac | 0x002d92 | 0x03623e | TEXT_HUFF | S |
| … | … | … | … | … | … | … |
| 60509 | 0xec5d | 0x85b060 | 0x000157 | 0x85b1b7 | INIT_SPRITE | R |
| 60508 | 0xec5c | 0x85af90 | 0x0000c4 | 0x85b054 | INIT_SPRITE | R |
| 60507 | 0xec5b | 0x85aeb0 | 0x0000d6 | 0x85af86 | INIT_SPRITE | R |
| 60506 | 0xec5a | 0x85ad80 | 0x00012e | 0x85aeae | INIT_SPRITE | R |
| 60505 | 0xec59 | 0x85ac90 | 0x0000ea | 0x85ad7a | INIT_SPRITE | R |
| … | … | … | … | … | … | … |
| 60400 | 0xebf0 | 0x1968e4 | 0x00bfca | 0x1a28ae | SCRIPT_MOD | S |
| 60302 | 0xeb8e | 0x805c50 | 0x000ac9 | 0x806719 | RNC | R |
| 60301 | 0xeb8d | 0x000e06 | 0x000fbd | 0x001dc3 | MOUSE | R |
| 60300 | 0xeb8c | 0x000c77 | 0x00018f | 0x000e06 | MOUSE | R |
| … | … | … | … | … | … | … |
| 60150 | 0xeaf6 | 0x001dc3 | 0x0017f0 | 0x0035b3 | FONT | S |
| … | … | … | … | … | … | … |
| 60110 | 0xeace | 0x000300 | 0x000977 | 0x000c77 | RNC | HR |
| 60101 | 0xeac5 | 0x0d6def | 0x001a2f | 0x0d881e | RNC | HR |
| 60100 | 0xeac4 | 0x0cb5e2 | 0x00b80d | 0x0d6def | RNC | HR |
| 60098 | 0xeac2 | 0x141e0e | 0x013a61 | 0x15586f | RNC | HR |
| 60097 | 0xeac1 | 0x12c665 | 0x0157a9 | 0x141e0e | RNC | HR |
| 60096 | 0xeac0 | 0x124796 | 0x007ecf | 0x12c665 | RNC | HR |
| … | … | … | … | … | … | … |
FLAGS:
H = include_header (bit 22).
Indica que al cargar el recurso se incluye el header
struct sal principio del buffer descomprimido. Si no está este bit, el loader descarta el header y entrega solo datos.S = skip_decomp (bit 23).
Indica que no se intenta descomprimir, aunque el recurso esté comprimido. Se usa para recursos que ya vienen sin compresión o que no deben pasar por el unpack.
R = compresión RNC.
El struct s (generalmente usado para gráficos/sprites) tal cual se define en el código ASM original para PC (Struc.asm), tiene los siguientes campos:
;------------------------------------------------------------------------------
; The header at the beginning of all data files
s struc
flag dw ? ;bit 0: set for colour data, clear for not
;bit 1: set for compressed, clear for uncompressed
;bit 2: set for 32 colours, clear for 16 colours
s_x dw ?
s_y dw ?
s_width dw ?
s_height dw ?
s_sp_size dw ?
s_tot_size dw ?
s_n_sprites dw ?
s_offset_x dw ?
s_offset_y dw ?
s_compressed_size dw ?
s ends
NOTA: Podéis descargar el código fuente original de la versión para PC, en ASM, aquí
Como vemos, si se necesita conservar/acceder a los “metadatos” del recurso que está extrayendo del fichero de recursos, se mantendrá la cabecera (flag H).
Idiomas
En el caso concreto de la traducción, los recursos de texto detectados son los siguientes:
| Idioma | ID | Recursos de texto |
|---|---|---|
| English | 0 | 60600-60607 |
| German | 1 | 60608-60615 |
| French | 2 | 60616-60623 |
| American | 3 | 60624-60631 |
| Swedish | 4 | 60632-60639 |
| Italian | 5 | 60640-60647 |
| Portug. | 6 | 60648-60655 |
| Spanish | 7 | 60656-60663 |
Echando un vistazo al código de la versión PC (Text.asm:11-12) vemos que la primera sección de texto es 77 y que hay 8 secciones de texto:
first_text_sec equ 77
no_of_text_sections equ 8
Luego podemos ver que hay un proc llamado get_text (Text.asm:716) que se encarga de cargar y extraer el texto. En esta función, se usa como base 60600 para luego sumarle el índice del idioma * número de secciones de texto y finalmente la sección.
Esto nos deja con esta fórmula:
file_id = 60600 + (language_index * no_of_text_sections) + section_index
Los language_index aparecen en Include.asm:76:
english_code equ 0
german_code equ 1
french_code equ 2
usa_code equ 3
swe_code equ 4
iti_code equ 5
por_code equ 6
spa_code equ 7
Por lo que si queremos obtener el primer fichero de textos en español 60656, sería así:
language_index(ES) = 7no_of_text_sections= 8section_index(primer bloque) = 0
Que sería tal que así:
file_id = 60600 + (7 * 8) + 0 = 60656
Una vez localizados los recursos de texto, solo nos falta extraerlos. Para ello, hemos hecho un script que parsea el el fichero índice SKY.DNR y extrae todos los recursos.
Una vez extraídos, sólo tenemos que localizar el árbol Huffman y decodificar los ficheros de recursos de texto (60656-60663). Veremos el tema de Huffman más adelante.
Recursos de Amiga
Extraer los ficheros de Amiga no tuvo misterio ya que se pueden encontrar los ficheros directamente en la estructura de directorios tanto de los disquetes como del pack de WHDLoad. El problema es que los ficheros de recursos de texto no son un fichero con una frase detrás de otra. En realidad, cada fichero tiene lo siguiente:
- Dos tablas de índice. Útil para saltar rápidamente al mensaje que queramos sin decodificar todo el bitstream.
- Un stream de bits comprimido con Huffman que contiene el texto.
Cuando el juego quiere leer el mensaje 207, por ejemplo, calcula el offset usando las tablas del fichero y empieza a decodificar bits justo en ese offset.
Para entenderlo mejor, imagina un libro donde:
- Las frases están comprimidas.
- Hay un índice que dice cuántas frases has de saltar para llegar a la que quieres leer.
El motor del juego lo que hace es:
- Mirar el índice.
- Saltar al sitio exacto.
- Decodificar la frase hasta el terminador (en este caso se usa
0x00).
Tenemos los siguientes ficheros disponibles en la versión de Amiga:
| Ruta | Fichero | Sección |
|---|---|---|
| data/disk_0/78 | 78 | 78 |
| data/disk_2/79 | 79 | 79 |
| data/disk_8/80 | 80 | 80 |
| data/disk_12/81 | 81 | 81 |
| data/disk_5/82 | 82 | 82 |
| data/disk_4/83 | 83 | 83 |
Estos ficheros son comunes a todas las versiones de BASS para Amiga. El lector que haya estado atento, se habrá dado cuenta de que faltan las secciones 77 y 84. ¡Efectivamente! Estas secciones están embebidas en el fichero ejecutable del juego y no siguen la misma estructura que comentamos a continuación. Esto lo cubrimos más adelante.
Header de recurso de texto
El header de cada fichero de texto (78..83) de Amiga tiene lo siguiente:
0x00..0x15 reservado Tamaño del fichero en 0x0C
0x16..0x17 singles_off (u16 BE, relativo a 0x16)
0x18..0x19 huff_off (u16 BE, relativo a 0x16)
0x1A.. block32[] (N * u16 BE)
... singles[] (N * 32 bytes)
... (padding opcional)
... bitstream Huffman
En el caso del fichero 78, queda tal que así:
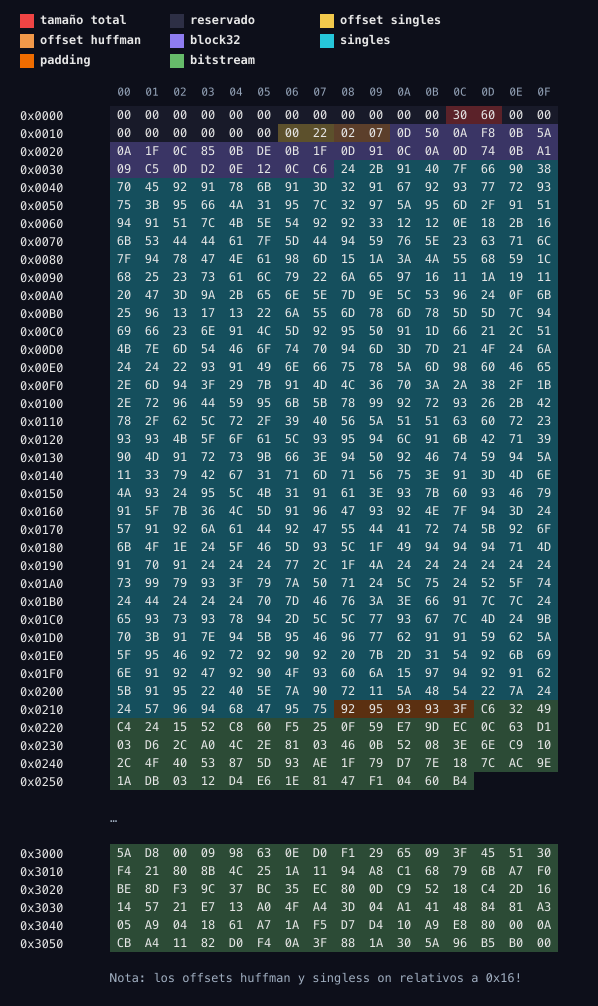
Qué es cada campo?
block32[]: Se trata del índice gordo. Aquí tenemos un índice de varios bloques de 32 mensajes. Cada bloque guarda la suma total (en db) del bloque. Es decir:
block32[0]= tamaño (db) de los mensajes 0..31block32[1]= tamaño (db) de los mensajes 32..63block32[2]= tamaño (db) de los mensajes 64..95- etc.
singles[]: Se trata del índice fino. Aquí nos dice cuanto ocupa cada mensaje individual dentro de un bloque concreto (en db).
Son dos índices diferentes, un índice se encarga de organizar los bloques de 32 en 32, el otro índice lleva qué mensajes están dentro de cada bloque individual. De esta manera, el motor puede saltar rápido a la string que quiere mostrar en ese momento en lugar de tener que decodificar todo el bitstream y luego buscar la string. Ejemplo:
Mensajes: 0..31 | 32..63 | 64..95
block32 : [ A ] [ B ] [ C ]
Para buscar msg 45:
bloque = 45 // 32 = 1
dentro = 45 % 32 = 13
start_db = block32[0] # A
+ sum(singles[32..44]) # 13 mensajes dentro del bloque 1
start_bits = start_db * 2
Double-bits (db)
Los offsets en el header (singles_off y huff_off) son relativos a 0x16 (después de la cabecera), no al inicio del fichero. Además, el motor usa una unidad custom llamada db o double-bits.
Huffman trabaja bit a bit, por lo que ir saltando por todo el bitstream usando bytes en los índices (8 bits) es inviable ya que es demasiado. De igual manera, ir saltando por el índice usando solo un bit sería muy preciso, pero el índice sería gigantesco. Con estas limitaciones, parece que llegaron al término medio donde utilizan 2 bits.
En este motor, el db (double-bit) no es un tipo estándar de Amiga ni de C, es una unidad de medida interna creada ad-hoc para este sistema de texto, ya que el motor no almacena los offsets de las strings en bytes, sino en db y hace la conversión a bits justo antes de decodificar el texto.
Para clarificar un poco lo de antes, block32[] y singles[] son un array de tamaños:
block32[i] = suma (db) de los 32 mensajes del bloque i
singles[j] = tamaño (db) del mensaje j dentro del bloque i
Y el motor calcula:
start_db = sum(block32[i]) + sum(singles[j])
start_bits = start_db * 2
start_bits corresponde al puntero real dentro del bitstream de Huffman.
Visualmente quedaría algo así:
block32[] (saltos por bloques de 32)
[B0] [B1] [B2] [B3] ...
| | | |
v v v v
singles[] (saltos por mensaje dentro de bloque)
M0 M1 M2 ... M31 | M32 M33 ...
| | | | |
v v v v v
bitstream Huffman (todo concatenado)
[.............bits.............]
Ejemplo simple:
Si singles[5] = 13:
13 db = 26 bits
Si el offset acumulado es start_db = 120:
start_bits = 120 * 2 = 240 bits
El motor empieza a decodificar Huffman exactamente en ese bit.
Inventario de mensajes por fichero
Además, con la información de la cabecera se puede saber exactamente cuantos mensajes hay en cada fichero. Por ejemplo, en el fichero disk_0/78 tenemos lo siguiente:
;----------------------------------------
; Cálculo del número de bloques y mensajes
; del fichero data/disk_0/78
singles_off = 0x22
huff_off = 0x207
base = 0x16
singles_abs = 0x38
huff_abs = 0x21D
---
block32_count = (singles_off - 4) / 2
num_msgs = block32_count * 32
--
(0x22 - 4) / 2 = 15 entradas/bloques
15 * 32 = 480 mensajes
Recordemos que los offsets son relativos a 0x16. Para calcular el número de bloques debemos tener en cuenta que entre 0x16 y el inicio de block32[] hay 4 bytes que corresponden a singles_off y huff_off, que son los offsets de donde empieza el índice de singles[] y el bitstream Huffman respectivamente. Además, cada entrada de block32[] son 2 bytes, de ahí sacamos block32_count = (singles_off - 4) / 2.
Igual con esta imagen se entiende mejor:

Mapa de recursos PC - AMIGA
Antes de pasar a la siguiente sección dedicada a Huffman, os dejo una tabla con el mapeo de recursos de texto entre PC y Amiga:
| id recurso PC (ES) | id seccion PC | tipo recurso Amiga | id recurso Amiga |
|---|---|---|---|
| 60600+(7*8)+0 = 60656 | 77 (0x4D) | embebido (exe) Seccion A | 0x4D (A) |
| 60600+(7*8)+1 = 60657 | 78 (0x4E) | fichero en disco | 78 |
| 60600+(7*8)+2 = 60658 | 79 (0x4F) | fichero en disco | 79 |
| 60600+(7*8)+3 = 60659 | 80 (0x50) | fichero en disco | 80 |
| 60600+(7*8)+4 = 60660 | 81 (0x51) | fichero en disco | 81 |
| 60600+(7*8)+5 = 60661 | 82 (0x52) | fichero en disco | 82 |
| 60600+(7*8)+6 = 60662 | 83 (0x53) | fichero en disco | 83 |
| 60600+(7*8)+7 = 60663 | 84 (0x54) | embebido (exe) Seccion B | 0x54 (B) |
Notas:
- En Amiga solo 78..83 están en disco.
- 77 y 84 están embebidas en el exe (A y B).
- El orden coincide con PC (77..84), solo cambia dónde se almacenan.
Huffman
Viendo el código fuente de ScummVM para el motor sky, ya vimos que se usaba texto comprimido con Huffman para la versión PC. Tenéis los árboles Huffman ya montados aquí.
Visto lo visto, no era de extrañar que en la versión de Amiga se hiciera lo mismo.
Lo cualo?
Vayamos por partes. Ya hemos visto anteriormente que el juego guarda el texto en una tira de bits comprimida, por bloques, en diferentes ficheros. Para convertir esos bits en letras, el juego sigue lo que vendría a ser una especie de árbol de decisiones:
- Lee un bit:
- Si es
0, va a la izquierda del árbol. - Si es
1, va a la derecha del árbol.
- Si es
- Repite hasta llegar a una hoja (en este caso un byte, por ejemplo
0x65, que el motor traduce al caracter'e').
Podríamos decir que Huffman es una manera de comprimir texto usando códigos de longitud variable. Esto es:
- Las letras frecuentes tienen códigos cortos (menos bits). Están más cerca del inicio del árbol ya que se usan frecuentemente y es más fácil acceder a ellas.
- Las letras raras o poco utilizadas tienen códigos largos (más bits). Dado que se usan poco, están más lejos del inicio del árbol y, en consecuencia, el camino hacia ellas es más largo.
Árbol de ejemplo (ejecutable SteelSky DE)
Un ejemplo, sacado del ejecutable de la versión Alemana de Amiga sería algo como esto:
[b0] - Ejemplo del árbol Huffman versión Amiga (DE)
├─0
│ ├─0
│ │ ├─0
│ │ │ └─1 → 0x65 'e' bits: 0001
│ │ └─1
│ │ ├─0 → 0x61 'a' bits: 0010
│ │ └─1 → 0x6E 'n' bits: 0011
│ └─1
│ ├─0
│ │ ├─0
│ │ │ ├─0 → 0x69 'i' bits: 01000
│ │ │ └─1 → 0x74 't' bits: 01001
│ │ └─1 → 0x73 's' bits: 0101
│ └─1
│ ├─0
│ │ ├─0 → 0x72 'r' bits: 01100
│ │ └─1 → 0x2E '.' bits: 01101
│ └─1 → 0x6F 'o' bits: 0111
└─1
├─0
│ ├─0
│ │ ├─0
│ │ │ ├─0
│ │ │ │ ├─0 → 0x00 '<NUL>' bits: 100000
│ │ │ │ └─1 → 0x45 'E' bits: 100001
│ │ │ └─1 → 0x75 'u' bits: 10001
│ │ └─1
│ │ ├─0
│ │ │ ├─0 → 0x6D 'm' bits: 100100
│ │ │ └─1 → 0x6C 'l' bits: 100101
│ │ └─1 → 0x49 'I' bits: 10011
│ └─1
│ ├─0
│ │ ├─0
│ │ │ ├─0 → 0x64 'd' bits: 101000
│ │ │ └─1 → 0x52 'R' bits: 101001
│ │ └─1
│ │ ├─0 → 0x41 'A' bits: 101010
│ │ └─1 → 0x4E 'N' bits: 101011
│ └─1
│ ├─0
│ │ ├─0 → 0x54 'T' bits: 101100
│ │ └─1 → 0x68 'h' bits: 101101
│ └─1 → 0x53 'S' bits: 10111
...
Dónde está el árbol? (AMIGA)
En el caso de Amiga, el árbol no está guardado como datos en ningún fichero, sino como código 68000. Aquí os dejo un snippet:
; Root (DE): 0x00BDCC
; Bitreader: 0x00C348
; Offset de inicio de hunk de código: 0x2C (44 bytes)
; Offset de fichero del root: 0x00BDCC + 0x2C = 0x00BDF8
; Root del árbol Huffman (dir. lógica 0x00BDCC, file_off 0x00BDF8)
; Cada bsr.w lee 1 bit; bne.w = bit=1 (rama derecha), si no = bit=0 (izquierda)
0x00BDCC: bsr.w $C348 ; leer bit #1
0x00BDD0: bne.w $BDDA ; bit=1 -> hoja 'n'
0x00BDD4: move.w #$61, d0 ; hoja: 0x61 = 'a'
0x00BDD8: rts
0x00BDDA: move.w #$6E, d0 ; hoja: 0x6E = 'n'
0x00BDDE: rts
0x00BDE0: bsr.w $C348 ; leer bit #2 (si venimos por otra rama)
0x00BDE4: bne.w $BE0A ; bit=1 -> subárbol (más profundo)
0x00BDE8: bsr.w $C348 ; leer bit #3
0x00BDEC: bne.w $BE04 ; bit=1 -> hoja 's'
0x00BDF0: bsr.w $C348 ; bit=0 -> otro nivel
0x00BDF4: bne.w $BDFE ; bit=1 -> hoja 't'
0x00BDF8: move.w #$69, d0 ; hoja: 0x69 = 'i'
0x00BDFC: rts
0x00BDFE: move.w #$74, d0 ; hoja: 0x74 = 't'
0x00BE02: rts
0x00BE04: move.w #$73, d0 ; hoja: 0x73 = 's'
0x00BE08: rts
0x00BE0A: bsr.w $C348 ; leer bit #4
0x00BE0E: bne.w $BE26 ; bit=1 -> hoja 'o'
0x00BE12: bsr.w $C348 ; bit=0 -> otro nivel
0x00BE16: bne.w $BE20 ; bit=1 -> hoja '.'
0x00BE1A: move.w #$72, d0 ; hoja: 0x72 = 'r'
0x00BE1E: rts
0x00BE20: move.w #$2E, d0 ; hoja: 0x2E = '.'
0x00BE24: rts
0x00BE26: move.w #$6F, d0 ; hoja: 0x6F = 'o'
0x00BE2A: rts
Aquí el bitreader:
; Bitreader (dir. lógica 0x00C348, file_off 0x00C374)
; d1 = índice de bit (0..7), d2 = byte actual, a0 = puntero al bitstream
0x00C348: dbra d1, $C352 ; d1-- ; si d1 >= 0, salta a test
0x00C34C: move.b (a0)+, d2 ; d1 < 0 -> leer nuevo byte
0x00C34E: move.w #$7, d1 ; reset d1 = 7
0x00C352: btst.l d1, d2 ; test bit d1 del byte
0x00C354: rts
Dónde está el árbol? (PC)
En el caso del código original de PC es exactamente igual, podéis ver Decoder.asm:1-120 (get_tbit), usado por Decodee.asm:10-14 (get_text_char), que a su vez es usado por Text.asm:804-833 (text_loop). Quedaría algo así:
text_loop - Text.asm
└─ get_text_char - Decodee.asm
└─ call get_tbit - Decoder.asm ; bit 0
├─ 0 → call get_tbit ; bit 1
│ ├─ 0 → call get_tbit
│ │ ├─ 0 → ' ' (leaf)
│ │ └─ 1 → 'e' (leaf)
│ └─ 1 → call get_tbit
│ ├─ 0 → 'o'
│ └─ 1 → 's'
└─ 1 → call get_tbit ; bit 1
├─ 0 → ...
└─ 1 → ...
Este árbol es imprescindible si queremos obtener el texto en claro ya que literalmente nos permite:
- Decodificar los textos originales en alemán.
- Codificar los textos en español usando el mismo árbol para que el ejecutable los pueda leer.
De Huffman a pintar texto
Durante mis divagaciones en el canal de Telegram de SCP, el señor DaRaSCo me comentó que había localizado la fuente del juego dentro del binario usando esta herramienta. Así pues, me puse manos a la obra para intentar extraerla y poder generar un mapa de la fuente para tener claro qué glifos teníamos disponibles.
La sorpresa fue encontrar dos tipografías. Una más gruesa que la otra. Parece ser que una se usa para mostrar diálogos y texto en el juego/UI. La otra puede ser que se use para los créditos?
Sea como sea, aquí tenéis los font maps, primero el de la fuente THICK:
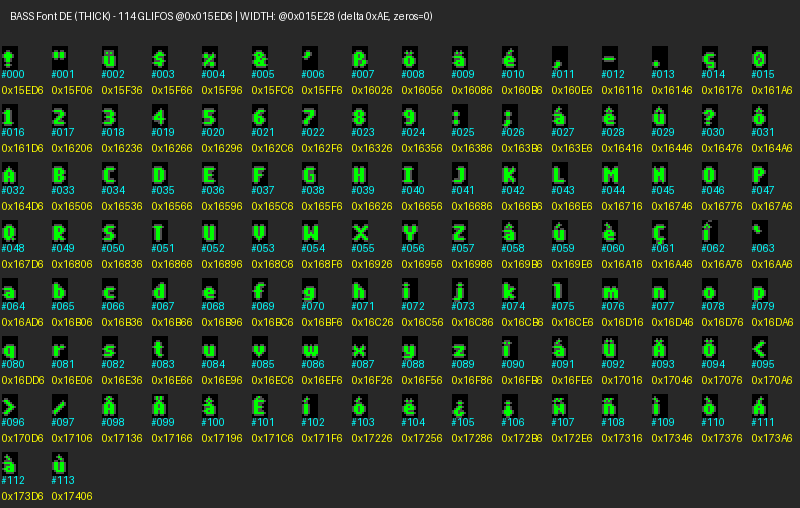
Luego el de la fuente THIN:
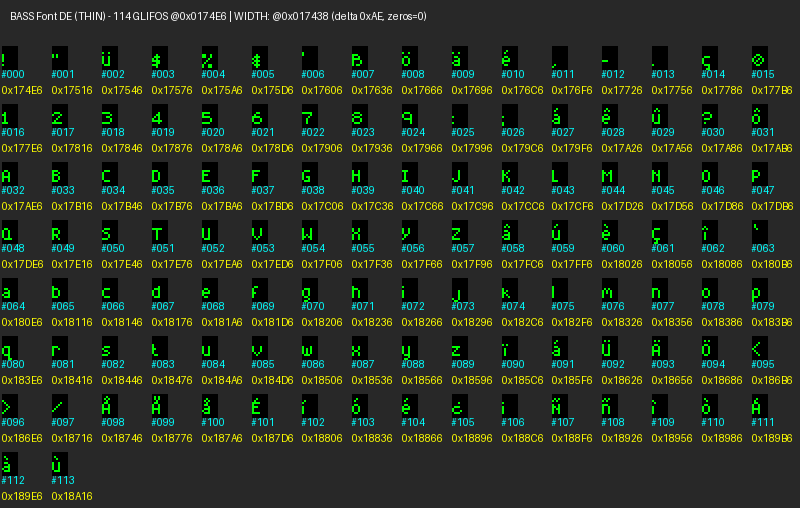
En cyan he puesto el índice dentro del bloque de la fuente y en amarillo el offset del glifo en el ejecutable. A partir de los offsets 0x15ED6 y 0x174E2 para la fuente THICK y THIN respectivamente, empiezan a verse los glifos.
El índice es esencial debido a cómo el motor pinta la fuente. Una vez que Huffman produce bytes (hojas), el motor no usa ese byte y lo pasa a Unicode/ASCII: usa esos bytes como códigos internos para ubicar el glifo y pintarlo.
Por ejemplo, para obtener el índice de la fuente THICK hacemos lo siguiente:
font_base = 0x15ED6
width_table = 0x15E28
glyph_index = byte - 0x21
bitmap_ptr = font_base + (glyph_index * 48) # tamaño 8x12, 2 bitplanes = 48 bytes
width = width_table[glyph_index]
Un ejemplo sacado del árbol Huffman original Alemán, para Amiga, con el byte (hoja) 0x7E (corresponde a Ä):
byte = 0x7E
glyph_index = 0x7E - 0x21 = 0x5D (93)
bitmap_ptr = 0x15ED6 + 0x5D*48 = 0x17046 (THICK)
width = width_table[0x5D]
Si miramos el font map de arriba para la fuente THICK, veremos que si buscamos el offset 0x17046 (en amarillo en la etiqueta), podemos ver el glifo correspondiente a Ä, cuyo índice es el #93.
¿Por qué le restamos 0x21 al byte del Huffman?
Porque el primer glifo real de la fuente corresponde al byte 0x21 ('!').
0x00 y 0x0A son control (fin/salto), y 0x20 es espacio (no tiene bitmap, evidentemente). Así que la tabla de glifos empieza en !, quedando así:
idx 0 -> byte 0x21 ('!')
idx 1 -> byte 0x22 ('"')
idx 2 -> byte 0x23 ('ü')
...
Tabla Hoja Huffman | Byte | Bits | IDX Glifo | Carácter
Aquí os dejo una tabla con todo lo que hemos cubierto entre Huffman + fuente:
| Leaf | Byte | Bits | Glifo idx | Glifo (DE) |
|---|---|---|---|---|
| 19 | 0x00 |
100000 |
- | <NUL> |
| 184 | 0x09 |
11111111111100 |
- | <OUT> |
| 60 | 0x21 |
1101100 |
0 | ! |
| 169 | 0x22 |
11111111110001 |
1 | " |
| 123 | 0x23 |
1111110100 |
2 | ü |
| 180 | 0x24 |
11111111111010 |
3 | $ |
| 185 | 0x25 |
11111111111101 |
4 | % |
| 158 | 0x26 |
1111111110001 |
5 | & |
| 67 | 0x27 |
11100000 |
6 | ' |
| 132 | 0x28 |
11111110001 |
7 | ß |
| 107 | 0x29 |
111110011 |
8 | ö |
| 90 | 0x2A |
11110011 |
9 | ä |
| 111 | 0x2B |
111110101 |
10 | é |
| 77 | 0x2C |
11101001 |
11 | , |
| 99 | 0x2D |
11110111 |
12 | - |
| 13 | 0x2E |
01101 |
13 | . |
| 160 | 0x2F |
111111111001 |
14 | ç |
| 138 | 0x30 |
11111110100 |
15 | 0 |
| 139 | 0x31 |
11111110101 |
16 | 1 |
| 135 | 0x32 |
11111110011 |
17 | 2 |
| 142 | 0x33 |
11111110111 |
18 | 3 |
| 152 | 0x34 |
111111110101 |
19 | 4 |
| 162 | 0x35 |
1111111110100 |
20 | 5 |
| 163 | 0x36 |
1111111110101 |
21 | 6 |
| 168 | 0x37 |
11111111110000 |
22 | 7 |
| 154 | 0x38 |
11111111011 |
23 | 8 |
| 151 | 0x39 |
111111110100 |
24 | 9 |
| 126 | 0x3A |
1111110110 |
25 | : |
| 124 | 0x3C |
1111110101 |
27 | á |
| 146 | 0x3D |
111111110000 |
28 | ê |
| 174 | 0x3E |
1111111111011 |
29 | û |
| 76 | 0x3F |
11101000 |
30 | ? |
| 177 | 0x40 |
11111111111000 |
31 | ô |
| 33 | 0x41 |
101010 |
32 | A |
| 82 | 0x42 |
1110111 |
33 | B |
| 53 | 0x43 |
1101000 |
34 | C |
| 47 | 0x44 |
110001 |
35 | D |
| 20 | 0x45 |
100001 |
36 | E |
| 87 | 0x46 |
11110001 |
37 | F |
| 79 | 0x47 |
1110101 |
38 | G |
| 63 | 0x48 |
110111 |
39 | H |
| 27 | 0x49 |
10011 |
40 | I |
| 94 | 0x4A |
111101001 |
41 | J |
| 89 | 0x4B |
11110010 |
42 | K |
| 50 | 0x4C |
110011 |
43 | L |
| 61 | 0x4D |
1101101 |
44 | M |
| 34 | 0x4E |
101011 |
45 | N |
| 45 | 0x4F |
1100001 |
46 | O |
| 68 | 0x50 |
11100001 |
47 | P |
| 117 | 0x51 |
1111110001 |
48 | Q |
| 31 | 0x52 |
101001 |
49 | R |
| 40 | 0x53 |
10111 |
50 | S |
| 37 | 0x54 |
101100 |
51 | T |
| 57 | 0x55 |
1101011 |
52 | U |
| 86 | 0x56 |
11110000 |
53 | V |
| 96 | 0x57 |
11110101 |
54 | W |
| 134 | 0x58 |
11111110010 |
55 | X |
| 110 | 0x59 |
111110100 |
56 | Y |
| 116 | 0x5A |
1111110000 |
57 | Z |
| 181 | 0x5B |
11111111111011 |
58 | â |
| 147 | 0x5C |
111111110001 |
59 | ú |
| 120 | 0x5D |
1111110011 |
60 | è |
| 165 | 0x5E |
111111111011 |
61 | Ç |
| 178 | 0x5F |
11111111111001 |
62 | î |
| 149 | 0x60 |
11111111001 |
63 | ` |
| 3 | 0x61 |
0010 |
64 | a |
| 72 | 0x62 |
1110010 |
65 | b |
| 44 | 0x63 |
1100000 |
66 | c |
| 30 | 0x64 |
101000 |
67 | d |
| 1 | 0x65 |
0001 |
68 | e |
| 73 | 0x66 |
1110011 |
69 | f |
| 49 | 0x67 |
110010 |
70 | g |
| 38 | 0x68 |
101101 |
71 | h |
| 7 | 0x69 |
01000 |
72 | i |
| 103 | 0x6A |
111110000 |
73 | j |
| 81 | 0x6B |
1110110 |
74 | k |
| 25 | 0x6C |
100101 |
75 | l |
| 24 | 0x6D |
100100 |
76 | m |
| 4 | 0x6E |
0011 |
77 | n |
| 15 | 0x6F |
0111 |
78 | o |
| 54 | 0x70 |
1101001 |
79 | p |
| 104 | 0x71 |
111110001 |
80 | q |
| 12 | 0x72 |
01100 |
81 | r |
| 10 | 0x73 |
0101 |
82 | s |
| 8 | 0x74 |
01001 |
83 | t |
| 22 | 0x75 |
10001 |
84 | u |
| 56 | 0x76 |
1101010 |
85 | v |
| 93 | 0x77 |
111101000 |
86 | w |
| 131 | 0x78 |
11111110000 |
87 | x |
| 70 | 0x79 |
1110001 |
88 | y |
| 98 | 0x7A |
11110110 |
89 | z |
| 188 | 0x7B |
111111111111110 |
90 | ï |
| 189 | 0x7C |
1111111111111110 |
91 | á |
| 141 | 0x7D |
11111110110 |
92 | Ü |
| 113 | 0x7E |
11111011 |
93 | Ä |
| 119 | 0x7F |
1111110010 |
94 | Ö |
| 171 | 0x80 |
1111111111001 |
95 | < |
| 173 | 0x81 |
1111111111010 |
96 | > |
| 187 | 0x82 |
11111111111110 |
97 | / |
| 127 | 0x83 |
1111110111 |
98 | Â |
| 106 | 0x85 |
111110010 |
100 | â |
| 190 | 0x86 |
1111111111111111 |
101 | É |
| 157 | 0x87 |
1111111110000 |
102 | í |
Cierre
Bueno, como primera aproximación al curro que nos hemos pegado mis amigos LLM y yo creo que no está nada mal. En este primer post de la serie que se viene, hemos cubierto lo siguiente:
- Introducción a BASS.
- Estructura de los ficheros de recursos de PC y extracción.
- Estructura de los ficheros de recursos de Amiga y extracción.
- Árboles de Huffman.
- Double-bits.
- Funcionamiento básico del motor de BASS para pintar el texto.
En el siguiente post terminaremos de ver qué otros recursos nos quedan por extraer que sean útiles para la traducción (o no), cómo parchear el juego (fuente) para mostrar glifos que no tienen correspondencia en el árbol Huffman y como usar la traducción oficial de PC en la versión de Amiga, reempaquetando de nuevo todos los recursos.